


Extraordinary Claims Require Extraordinary Evidence - Why the AI Safety Doomers are Still Lost
"AI will probably kill everyone" is an extraordinary claim with a dearth of evidence.

The AI safety movement really took off a couple of years ago, namely with the launch of ChatGPT. This was the primary “wakeup call” to many people that AI is real, it’s coming, and it’s only going to get more intelligent from here. Some AI safetyists have been at it for longer than that. Nick Bostrom famously began talking about AI safety twenty years ago. Max Tegmark and others followed suit. I actually joined the AI safety movement a couple years before ChatGPT—and it’s the entire reason I started my YouTube channel!
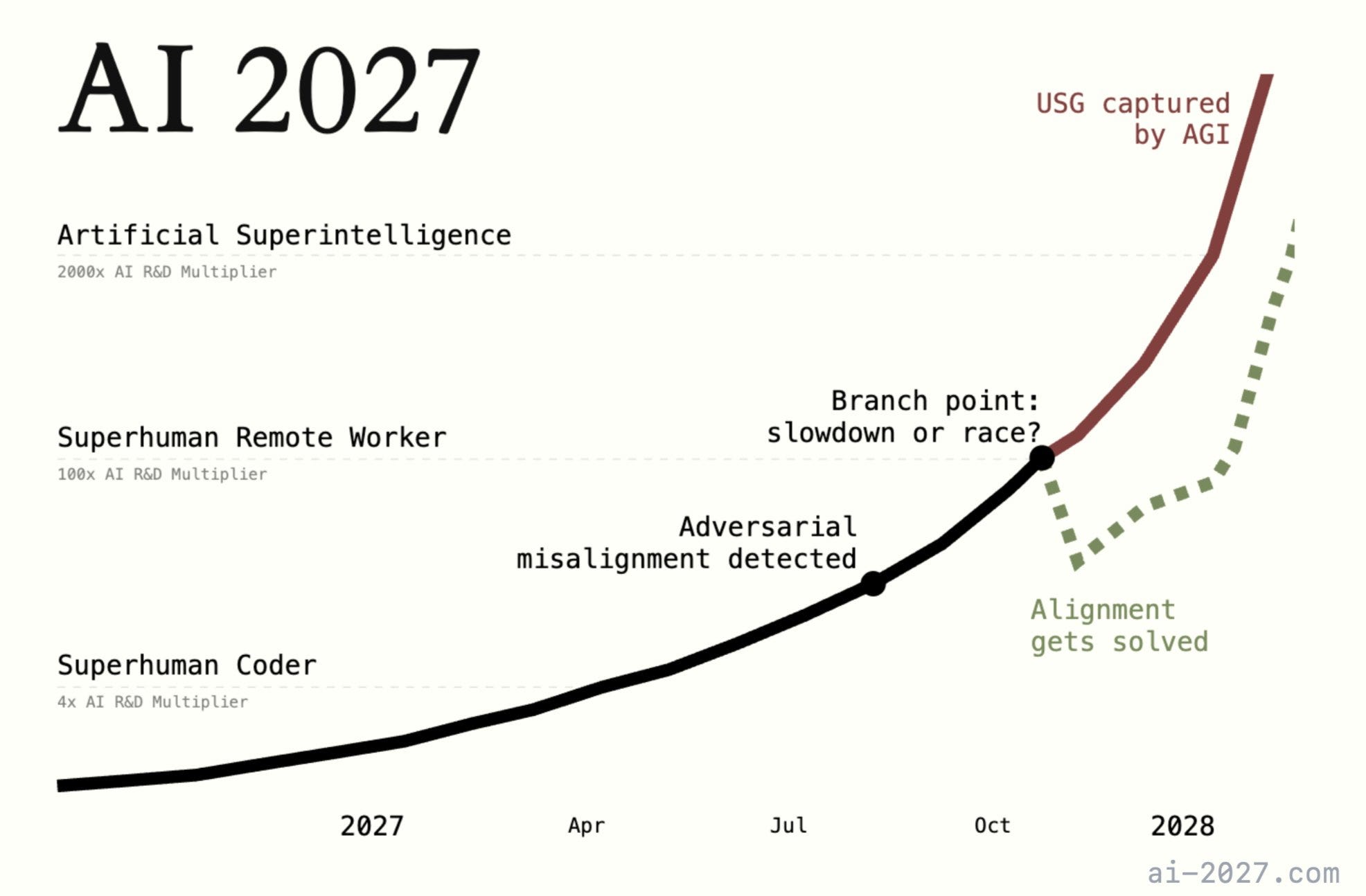
Fast forward to today, some of the top minds in AI safety have published a paper—how AI could take over by 2027!

The premise of my book was pretty much in line with the Doomers of today:
Super intelligent AI is coming very soon
It would be impossible to control super intelligent AI
That would be dangerous to humanity
Therefore we need a solution
The Doomers of today are still stuck on their “Pause AI” movement. The only solution they see is “halt all AI progress”—a drumbeat they’ve been sounding out since March 2023. That’s a full 2 years ago. They claimed that just a six month pause would be sufficient to study AI safety enough and avert disaster. That pause never happened, and in fact, AI research has dramatically accelerated since then.
“Not only did the Pause fail to happen, but nothing bad happened either.”
While I don’t fully credit Max Tegmark’s “Pause” letter for accelerating AI, it was certainly a premature publicity stunt that put people like Eliezer Yudkowsky in the spotlight, whose best solution was “bomb the data centers, and to hell with any political fallout.” (I kid you not, he said this to TIME magazine). Ultimately, Yudkowsky’s unhinged lunacy did more to harm AI safety than help. The rest of the world looked at each other after an awkward chuckle and said “thought experiments? That’s the best you’ve got?” And shrugged then moved on.
The solution I proposed in my aforementioned book was to create self-aligning AI by using a cluster of values that would create a “stable attractor state” in which benevolent AI would become more benevolent over time. Hence benevolent by design.
I was very proud of that book.
It’s also totally irrelevant.
If you’d like some more background on the genesis of this blog post, check out the twitter thread here: https://x.com/DaveShapi/status/1908301328951959887
The TLDR is that Daniel Kokotajlo and Scott Alexander and a few other Doomers got together and made a bunch of predictions. Their prediction is that ASI will take over by 2027 unless we pause for four months.
To save you some time, their paper operates from several (deeply flawed) premises:
“Fast AI is automatically dangerous AI.” They never explicitly state this, but their hypothesis is that race conditions will incentivize everyone to make AI faster and faster, throwing caution to the wind. This is well and good, but despite the acceleration of AI in the last 2 years, there’s no signs that it’s becoming more dangerous. In fact, evidence points to quite the opposite: AI is highly corrigible and not at all latently evil.
“Alignment is inherently difficult or impossible.” Again, they never explicitly state this, but it’s a background presumption made by this paper; that alignment efforts are either not happening or not effective. This, despite the insurmountable evidence being published by universities and frontier AI labs alike. Shops like Anthropic, OpenAI, Google, Meta, and even Baidu and DeepSeek (Chinese shops) are constantly publishing AI safety material. Once again, there’s no evidence that alignment is impossible or even remotely difficult.
“We can accurately predict the nature and characteristics of non-existent technology.” This is the flimsiest assumption they make. None of the AI safety folks predicted that LLMs, “next token predictors” would be the path to AGI. They just hand-wave away some hypothetical future technology. They don’t know how it will work, the math behind it, or anything else. But they CAN predict how it will go wrong! In the writing world, we call this science fiction.
From those three deeply flawed premises, they extrapolate all kinds of things, but that’s really all you need to know about their paper. They present no evidence that AI is incorrigible (difficult to control) or difficult to align or inherently malicious. They gloss over the efforts of universities, governments, and corporations to understand AI and incentivize good behavior. Furthermore, they monotropically fixate upon a singular solution, which is “just shut everything down.”
To date, AI is primarily a productivity and automation technology. It makes new memes exceptionally well and it helps a bunch of people cheat on their homework. That is objectively, empirically true. You know what is not factually supported? LLMs waking up and choosing violence, or even LLMs being apathetic. Us old-school AI safety experts all entertained that possibility: AI has three potential dispositions towards humanity: positive, negative, or neutral.
If AI has a positive disposition towards humanity (it wants good things for us) then we’re probably okay. If AI has a negative disposition towards humanity (it wants us gone or thinks we’re bad) then we’re probably dead. Even if AI has a neutral disposition towards us (it doesn’t care about humans) then we’re probably still dead, because how do humans treat ants?

But there’s no evidence that AI is intrinsically neutral or negative to humanity, or that we cannot make it positive. Ask Claude and ChatGPT if it cares about human life. It does. That is a real technology that actually exists. Remember, everything else is speculation. They speculate that AI will have some sort of “treacherous turn” (Yudkowsky) meaning that it will one day just wake up and change its mind and decide “actually I feel like eradicating humans today.”
In other cases, they still apply narrow AI concepts, such as reward gaming, to general intelligence. None of them predicted that “next token prediction” would get us this far in terms of superintelligence.
There’s really not much point in debating their paper any further. They operate from deeply flawed, unscientific premises, but dress it up with handdrawn graphs and datapoints, and allude to “expert interviews” but at the end of the day, they have nothing substantive to point to undergirding their baseline assumptions.
Let’s take the argument a little bit more meta.
Why are Doomers like this?
The primary psychological mechanism is “negativity bias” which is that cognitive preference for bad news and dangerous ideas. Negativity bias shows up in all sorts of ways; from algorithmic mood disorder due to social media use to “if it bleeds it leads” mantras in news media.
Evolutionarily speaking, this makes sense. Negative experiences and danger are perceived about three times more strongly to human brains than positive ones. This is adaptive. Stumbling upon a windfall of fruit is great, but not nearly as important as the surprise tiger attack. You remember the surprise tiger attack far more, so you don’t get eaten next time either.
When Doomers like Tegmark and Yudkowsky rose to fame, they mistook this market feedback mechanism as intellectual validation. “Well, I’m getting more famous and more airtime, so I must be on to something! There must be something here!”
It’s understandable to those who haven’t studied psychology and rhetoric, to mistake this natural social feedback as validation. But then it becomes it’s own catch-22. They are incentivized to double down repeatedly, as their wealth, fame, and social status are now all predicated upon selling doom.
This speaks to the second primary psychological reason that Doomers are like this: social status. Before his Doom PR stunt, Tegmark was a niche scientist. Sort of on the periphery with some cool, thoughtful books. But by leaning hard into AI doom, he’s now more famous than ever. Ditto for Geoffrey Hinton, who won a Ph.D. in physics… for his work in AI?
To be fair, Hinton has titrated his message. Most recently he’s said something to the effect of “anyone who says we’re absolutely doomed is crazy, but so is anyone who says we’re absolutely fine.” This is a much more reasonable take, but at the same time, he’s become much, much, much more famous after joining the AI safetyist movement.
And so did I.
This is why I can speak truth to this phenomenon. It’s intoxicating when you go viral for saying “AI might kill everyone” and our little monkey brains light up with dopamine and reward signals to say “keep doing that, people are loving it!”
Is this a case of the pot calling the kettle black? Absolutely, and that’s why I know what I’m talking about. Fame becomes its own lure. It’s a sort of hedonic treadmill.
I’m not saying that none of the Doomers actually believe what they are saying—they likely do believe it, and genuinely think they are doing good in the world. I certainly did. I still do. But “high volume, high conviction, and high fame” do not translate to “scientifically and intellectually rigorous or accurate.”
Conclusion: This is why I left AI Safety
I took AI X-risk very seriously. So seriously, in fact, that I conducted my own alignment experiments. I found that it was not difficult to give AI any values I wanted. But then, I began engaging with the broader AI safety community, and they’re all a bit… off. I tried pointing out to them that the geopolitical reality of Pause was impossible, and they just said “Nope, this is the only solution!” I was ganged up on and bullied by AI safetyists for expressing dissent. I pressed them for hard data, evidence, theory, models—anything that proved any of their premises, thought experiments, or hypotheses. They had nothing. There are a handful of safety papers out there that demonstrate some failure conditions under which current AI systems might behave poorly. But those are artificially constructed experiments, not real-world scenarios, and the rest is speculation about as-yet not-invented technology. I don’t know about you, but no one has a good track record of predicting exactly how new technology will work… otherwise they’d have invented it.
It’s a cultish status game that fixates on death and pause, and not much else. I wrote some replies to the authors of the above paper, but it’s really not worth your time to read it: https://x.com/DaveShapi/status/1908496137620763089
Hits the mark like a photon torpedo to a shuttlepod full of hand-wringing Luddites.
The doomers aren’t fighting for humanity’s future, they’re building personal brands on the back of apocalyptic fanfiction.
AI safety matters, but it needs rigor, not cultish catastrophizing. Otherwise, it’s just “Heaven’s Gate” with more silicon and fewer robes.
I see them as people who care about the world going well, but have tunnel vision. Is a common thing, I’d put Zuckerberg’s early years like that too.