

Something shifted in the past six months. If you work with AI systems daily, you felt it. Your tools started doing things that made you pause mid-task and stare at your screen. Benchmarks crossed thresholds that felt abstract a year ago. Engineers stopped sounding like hype men and started sounding like field reporters from a different decade. William Gibson said it a long time ago. The future is already here. It’s just not evenly distributed. That line used to feel like a clever observation about technology adoption curves and early access programs. Now it feels like a survival manual.
“The future is already here, it’s just not evenly distributed.” ~ William Gibson
The singularity stopped being a thought experiment sometime in the past year. Several trendlines crossed at once. Coding hit a psychological threshold. Science acceleration moved from theoretical to heavily capitalized. A chasm opened between people who use AI and people who understand it. Architectural breakthroughs made recursive improvement feel suddenly plausible. Some of us are watching AI systems write production code overnight while others still think ChatGPT looks up answers in a database. Both realities exist right now, in January 2026. The distribution has grown so uneven that people occupying different points along it might as well be living in different centuries.
The Coding Threshold
An Anthropic engineer named Boris confirmed late last year that 100% of his contributions to Claude Code are now written by Claude itself. Earlier in 2025 the figure was 80%. The human role collapsed from writing code to directing the AI and reviewing its output. Anthropic’s CEO has suggested that internal teams are operating in the 70 to 90 percent range for AI-authored code. These are production anecdotes from people building frontier systems. The people making the AI are already being replaced by the AI in the task of making the AI.
You should interpret these figures carefully. There is no standardized metric for what “percent of code” means. It could refer to tokens or lines or diffs or accepted pull requests or simply first drafts that get heavily edited. The ambiguity matters less than the trajectory. SWE-bench Verified tracks performance on 500 real open-source issues and has become the de facto benchmark for agentic coding. By mid-2025 the best systems were solving 65% of these issues. The leaderboard kept climbing. The gains came from scaffolding as much as raw model capability. Repo ingestion, test execution loops, patch validation, tool orchestration. The infrastructure for autonomous coding matured faster than anyone expected.
The practical result is that the interval between blank page and working draft has collapsed. The bottleneck moved. What remains defensible is systems architecture under real constraints, domain semantics, data quality and observability, eval design, security and compliance. The patterned and well-specified and locally testable work is exactly where AI excels. This is the psychological threshold that matters. When the tool routinely outperforms your own self-model in a domain you trained years to master, something breaks in how you relate to your expertise. Developers are hitting this wall right now. They are the canary.
The Comprehension Gap
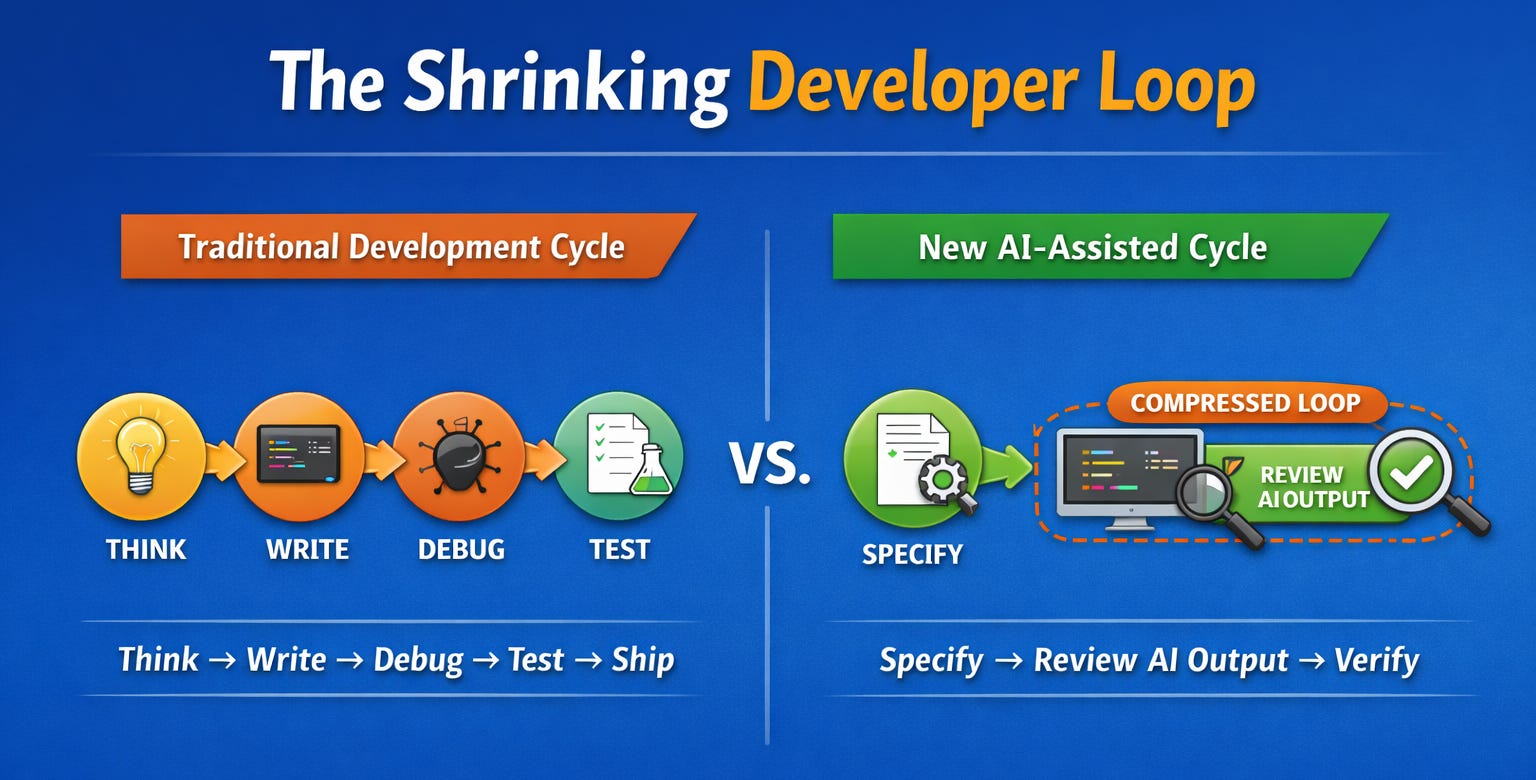
Pew Research reported in mid-2025 that 34% of American adults have used ChatGPT. That figure roughly doubled from 2023. Younger users skew much higher. By raw adoption numbers this looks like a technology going mainstream. It is not. A Searchlight Institute survey from December 2025 found that 45% of respondents believe ChatGPT works by looking up an exact answer in a database. Another 21% think it follows prewritten scripts. The dominant mental model is retrieval. Most people think they are using a very fancy search engine or a sophisticated decision tree. They have no conception of probabilistic generation or learned latent structure. They use the tool constantly and understand almost nothing about what it actually does.
This gap will make public trust volatile. Expect wild swings. A coding agent ships a feature that saves a company millions and believers multiply overnight. A hallucination causes a disaster and the backlash arrives just as fast. Salient successes breed trust spikes. Salient failures breed collapses. The comprehension gap means there is no stable foundation underneath any of it. People form opinions based on anecdotes and headlines because they lack the mental model to evaluate claims independently. The distance between AI users and AI understanders is widening every month.
Here is the psychological mechanism underneath all of this. When a tool routinely outperforms your self-model in a domain you respect, the equilibrium shifts abruptly. Coders are hitting this threshold right now. Scientists will hit it next. Everyone else follows. The shift feels like vertigo because it arrives suddenly even though the trendlines were visible for years. You cannot prepare for the emotional reality of being outclassed by a machine in the thing you trained your whole life to do.
Science is Accelerating
AI is already accelerating science in two distinct ways and most commentary collapses them into one. The near-term story is cognitive labor acceleration. Models now perform literature-scale synthesis, hypothesis generation, and meta-analysis at speeds no human team could match. Axios reported that 40 million people now turn to ChatGPT for health information queries. Even if you discount the marketing framing, the signal is clear. People are outsourcing quasi-expert synthesis in high-stakes domains right now. They are using AI to navigate medical literature, insurance questions, and treatment options. The marginal cost being compressed is cognition itself. Wet-lab throughput remains unchanged but the ability to survey and synthesize vast bodies of knowledge has jumped by orders of magnitude.
The second flavor is more discontinuous and involves physical loop closure. Models propose experiments. Robots execute them. Instruments read out results. Pipelines update beliefs automatically. This is the AI science factory thesis and it is being capitalized aggressively. Reuters covered Lila Sciences last October when it topped a 1.3 billion dollar valuation with fresh Nvidia backing. The company is building exactly this infrastructure with large lab footprints designed around closed-loop experimentation where AI systems generate hypotheses and automated equipment tests them continuously. The human role shrinks to oversight and strategic direction.
Why does everyone keep saying 2026? Dario Amodei has explicitly predicted that powerful AI systems capable of accelerating science will emerge by late 2026 or early 2027. His essay Machines of Loving Grace describes AI that can navigate interfaces, reason for extended periods, and control laboratory equipment. Peter Lee at Microsoft Research said that in 2026 AI will actively join the process of discovery in physics, chemistry, and biology. IBM and Stanford researchers have converged on similar timelines. Leopold Aschenbrenner’s Situational Awareness document gave 2027 a kind of totemic status in AI circles. The predictions cluster too tightly to ignore.
Aschenbrenner laid out the math. Roughly half an order of magnitude per year comes from increased compute. Another half comes from algorithmic efficiency gains. Additional gains arrive from unhobbling as systems move from chatbots to agents. His projection suggests that hundreds of millions of AGI-level systems could compress a decade of algorithmic progress into a single year or less. This sounds like science fiction until you look at the trendlines that got us here. GPT-2 to GPT-4 took us from preschooler-level abilities to smart high schooler abilities in four years. Another jump of similar magnitude lands somewhere that does not have a good name yet.
Hyperobjects and Normalcy Bias
There is a name for why most people cannot see what is coming. Psychologists call it normalcy bias. It is the cognitive tendency to disbelieve or minimize threat warnings even when evidence accumulates. Research on disasters suggests that about 80% of people display this bias when faced with genuine emergencies. They underestimate likelihood and downplay severity. Many wait for confirmation from others before acting at all. Our brains evolved in environments that were mostly stable across a human lifespan. Seasons changed but the underlying rules did not. We developed cognitive machinery optimized for local and geometric thinking because that is what survival required. This machinery constantly reasserts a frame that insists what you are experiencing right now is normal.
The philosopher Timothy Morton coined a term that helps explain what happens when phenomena exceed our cognitive grasp. He called them hyperobjects. A hyperobject is an entity so vastly distributed in time and space that it transcends spatiotemporal specificity. You cannot point to it and say that is the thing. Climate change is the canonical example. You can experience a tornado or a drought or a wildfire but you cannot experience global warming directly. The totality refuses to fit inside any particular local manifestation. Morton described hyperobjects as viscous because they adhere to whatever they touch and molten because they refute the idea of fixed spacetime. They appear only in local slices and seem to come and go depending on your vantage point. We lack what might be called object permanence for these things.
AI has become a hyperobject. Its capabilities are distributed across tools and companies and hidden workflows that most people never encounter. The average user experiences shallow slices through chat interfaces and text summaries and autocomplete suggestions. Cutting-edge users experience deep slices through overnight agents that refactor entire codebases and systems that propose novel experimental designs. These two groups occupy the same calendar year but inhabit different technological centuries. Gibson’s line about uneven distribution turns out to describe an information-access phenomenon more than a vibes-based observation. Some people have direct contact with systems that are genuinely transforming what is possible. Others interact with watered-down consumer products and reasonably conclude that the hype is overblown. Both groups are responding rationally to the slice of the hyperobject they can perceive.
Morton’s central insight about hyperobjects is that they feel abstract until late-stage visibility forces recognition. You can know intellectually that the climate is changing for decades before a hurricane destroys your house and makes the knowledge feel real. The same dynamic applies to AI. For half a century the singularity lived in science fiction novels and academic papers and TED talks. Now it is entering the phase where dismissal becomes difficult. Benchmarks keep crossing thresholds. Anecdotes keep piling up. Predictions from credible sources keep clustering around the same near-term window. The abstraction is condensing into something that demands a response. You can feel it if you are paying attention. The question is whether you will recognize it before or after it reshapes the ground beneath your feet.
Coherence and the Cognitive Lacuna
DeepSeek released a paper in January 2026 that solved a problem researchers had struggled with for years. When you make neural networks bigger, they tend to become unstable during training. Think of it like audio feedback in a microphone. A small signal enters the system, gets amplified as it passes through, gets amplified again, and suddenly you have an ear-splitting screech. Neural networks suffer from the same dynamic. Information passing between layers can get amplified thousands of times over, causing the whole training run to collapse. Companies have lost millions of dollars in compute costs to these failures. DeepSeek’s solution is elegant. They constrain how information moves between layers so that it stays balanced. Information can be shuffled around and redistributed but the total amount remains constant. Nothing gets amplified out of control. The math behind it uses a technique from 1967, which is a delightful detail—a sixty-year-old algorithm turns out to be exactly what was needed to stabilize the largest AI systems ever built.
Coherence is the technical substrate that makes recursive improvement possible and this paper addresses it directly. Stable training under more aggressive architectural choices enables several advances at once. Models maintain reasoning over longer horizons without drifting or collapsing. Agents execute complex tasks more reliably because their internal signals stay consistent. Outer loops where models help create the next generation of software and experiments become tighter and faster. Sebastian Raschka called the mHC paper a striking breakthrough that could shape the evolution of foundational models. He is not prone to hyperbole. When researchers who study these systems closely start using words like breakthrough, the signal is worth noting.
One frontier remains largely unexplored. Current models critique their own outputs but they do not reliably sense the shape of what remains unknown to them. A more advanced capability would involve identifying the highest-value missing variable in an explanation and then proposing experiments specifically designed to resolve that gap. This demands something beyond self-critique because it requires epistemic action selection under uncertainty. A model with this capacity would feel a kind of cognitive gradient pointing toward concepts it has not yet articulated and then take actions to close that gap without collapsing into confabulation. I have started calling this the ability to detect cognitive lacunae. Whether machines can develop it may determine how fast the recursive improvement loop actually spins.
The Visceral Experience
Emergent abilities keep appearing in places nobody thought to look. GPT-2 already possessed a rudimentary theory of mind but no researcher tested for it because the idea seemed absurd at the time. Years later someone ran the experiments and found the capability had been there all along, waiting to be measured. GPT-4 now scores 95% on false-belief tasks, matching near-adult human performance on assessments designed to detect whether a mind can model the beliefs of other minds. This pattern repeats across domains. Capabilities exist before we develop the benchmarks to detect them. We keep discovering that the future arrived earlier than we realized and simply went unnoticed.
The singularity feels real because the gap between science fiction and Tuesday has collapsed. The distribution remains uneven and will stay that way for some time. If you have read this far you probably occupy a position closer to the edge than most people around you. You have access to information and tools and context that the 45% who think ChatGPT searches a database will not encounter for years. The ground is moving whether you choose to acknowledge it or not. Recognition is the only variable still under your control.
Notes
William Gibson, interview by Scott Simon, NPR, November 30, 1999. The exact phrasing and original source of this quote remain disputed, with variations appearing across interviews and talks throughout the 1990s. It has become a touchstone in technology futurism for describing the uneven adoption curves of transformative tools.
Community reports from Anthropic engineers, compiled from developer discussions, late 2025. The specific engineer often identified as “Boris” has discussed these figures in various forums. While not formally published, these anecdotes represent firsthand accounts from people building frontier AI systems.
“Anthropic CEO Says 90% of Code Written by Teams at the Company Is AI-Generated,” Yahoo Tech, 2025, https://tech.yahoo.com/ai/claude/articles/anthropic-ceo-says-90-code-030401508.html. These figures should be interpreted carefully given the lack of standardized measurement, but the trajectory they describe is consistent across multiple Anthropic sources.
“SWE-bench Leaderboards,” SWE-bench, accessed January 2026, https://www.swebench.com/. SWE-bench Verified uses 500 real open-source issues to evaluate agentic coding systems. It has become the de facto benchmark for measuring autonomous software engineering capability.
“34% of U.S. Adults Have Used ChatGPT, About Double the Share in 2023,” Pew Research Center, June 25, 2025, https://www.pewresearch.org/short-reads/2025/06/25/34-of-us-adults-have-used-chatgpt-about-double-the-share-in-2023/. Pew’s longitudinal tracking provides the most reliable measure of ChatGPT adoption in the U.S. population.
“Americans Have Mixed Views of AI—and an Appetite for Regulation,” Searchlight Institute, December 2025, https://www.searchlightinstitute.org/research/americans-have-mixed-views-of-ai-and-an-appetite-for-regulation/. This survey provides rare quantitative data on public mental models of how AI systems actually function, revealing a widespread misunderstanding of generative AI as retrieval-based.
“Exclusive: 40 Million People Turn to ChatGPT for Health Care,” Axios, January 5, 2026, https://www.axios.com/2026/01/05/chatgpt-openai-health-insurance-aca. Even accounting for marketing framing, the scale of health-related queries indicates that people are already outsourcing quasi-expert synthesis in high-stakes domains.
“AI Lab Lila Sciences Tops $1.3 Billion Valuation with New Nvidia Backing,” Reuters, October 14, 2025, https://www.reuters.com/business/ai-lab-lila-sciences-tops-13-billion-valuation-with-new-nvidia-backing-2025-10-14/. The capitalization of closed-loop AI science infrastructure represents a major bet on physical automation of the research process.
Dario Amodei, “Machines of Loving Grace,” Anthropic, October 2024, https://www.anthropic.com/news/machines-of-loving-grace. Amodei’s essay outlines a vision of AI systems capable of sustained reasoning, interface navigation, and laboratory control by late 2026 or early 2027.
Peter Lee, “2026 Predictions,” Microsoft Research, December 2025. Lee predicts that AI will move from summarizing and answering to actively joining discovery processes in physics, chemistry, and biology during 2026.
Leopold Aschenbrenner, “Situational Awareness: The Decade Ahead,” June 2024. This 165-page document from a former OpenAI researcher has achieved significant influence in AI circles, particularly for its projection of AGI emergence by 2027 and its analysis of compute and algorithmic efficiency trendlines.
Research on normalcy bias in disaster response, synthesized from multiple sources. The 80% figure appears consistently across studies of emergency behavior, including analyses of Hurricane Katrina evacuation failures and 9/11 survivor accounts.
Timothy Morton, Hyperobjects: Philosophy and Ecology after the End of the World (Minneapolis: University of Minnesota Press, 2013). Morton’s framework describes entities so distributed in time and space that they resist direct perception. See also Nathan Heller, “Timothy Morton’s Hyper-Pandemic,” The New Yorker, 2020, https://www.newyorker.com/culture/persons-of-interest/timothy-mortons-hyper-pandemic.
DeepSeek AI, “mHC: Manifold-Constrained Hyper-Connections,” arXiv, January 2026, https://arxiv.org/pdf/2512.24880. This paper addresses training instability at scale by constraining information mixing to doubly stochastic matrices, enabling stable training of much larger models.
Sebastian Raschka, commentary on DeepSeek mHC paper, January 2026. Raschka is a widely respected researcher in machine learning whose assessment of the paper as a “striking breakthrough” carries significant weight.
Tech layoff data compiled from industry tracking sources, 2025. The 54,694 figure represents layoffs where employers explicitly cited AI as a factor, distinct from the broader 1.17 million tech layoffs recorded during the year.
Entry-level hiring analysis based on job posting data from the fifteen largest technology companies, comparing 2023 to 2024 figures. The 25% decline reflects a structural shift in how these companies approach junior talent acquisition.
U.S. Bureau of Labor Statistics, programmer employment data, 2023–2025. The 27.5% decline represents one of the steepest drops in a white-collar occupation recorded over a two-year period.
Computer science graduate employment data, National Association of Colleges and Employers, 2025. The 6.1% unemployment rate for new CS graduates is historically elevated for a field that previously enjoyed near-universal employment.
Stanford Institute for Human-Centered AI, study on software developer employment by age cohort, 2025. The finding that developers aged 22–25 experienced nearly 20% employment decline suggests that entry-level positions are disproportionately affected.
Survey of Indian IT workforce, 2025. India’s IT sector employs millions of workers in roles particularly susceptible to AI automation, making this sentiment data a leading indicator of broader global trends.
World Economic Forum, Future of Jobs Report 2025. The finding that 41% of employers intend to reduce workforce due to AI over five years represents a significant acceleration from previous editions of this report.
Consumer sentiment surveys, 2025. The 66% figure expecting unemployment to rise represents the highest level of employment pessimism recorded in a decade of tracking.
Michal Kosinski, “Theory of Mind May Have Spontaneously Emerged in Large Language Models,” arXiv, 2023. Kosinski’s research demonstrated that GPT models developed theory of mind capabilities without explicit training, with performance improving dramatically across model generations.
Kosinski, “Theory of Mind.” The finding that GPT-4 achieves 95% on false-belief tasks places it at near-adult human performance on assessments originally designed to study child cognitive development.
