

There’s a popular turn of phrase when criticizing LLMs—“the world is not made of words.”
This critique is levied at AI models as an argument that they cannot possibly have “world models.”
But first question: what is a “world model”? When you ask most people, what they describe is somewhere between a cognitive architecture and a sensorimotor feedback system.
They are generally not talking about an intuitive grasp of advanced physics and chemistry, which is what I would consider useful as a “world model.” Perhaps because LLMs already have an intuitive sense of most STEM topics?
No, what they are talking about is more akin to robotic control systems.
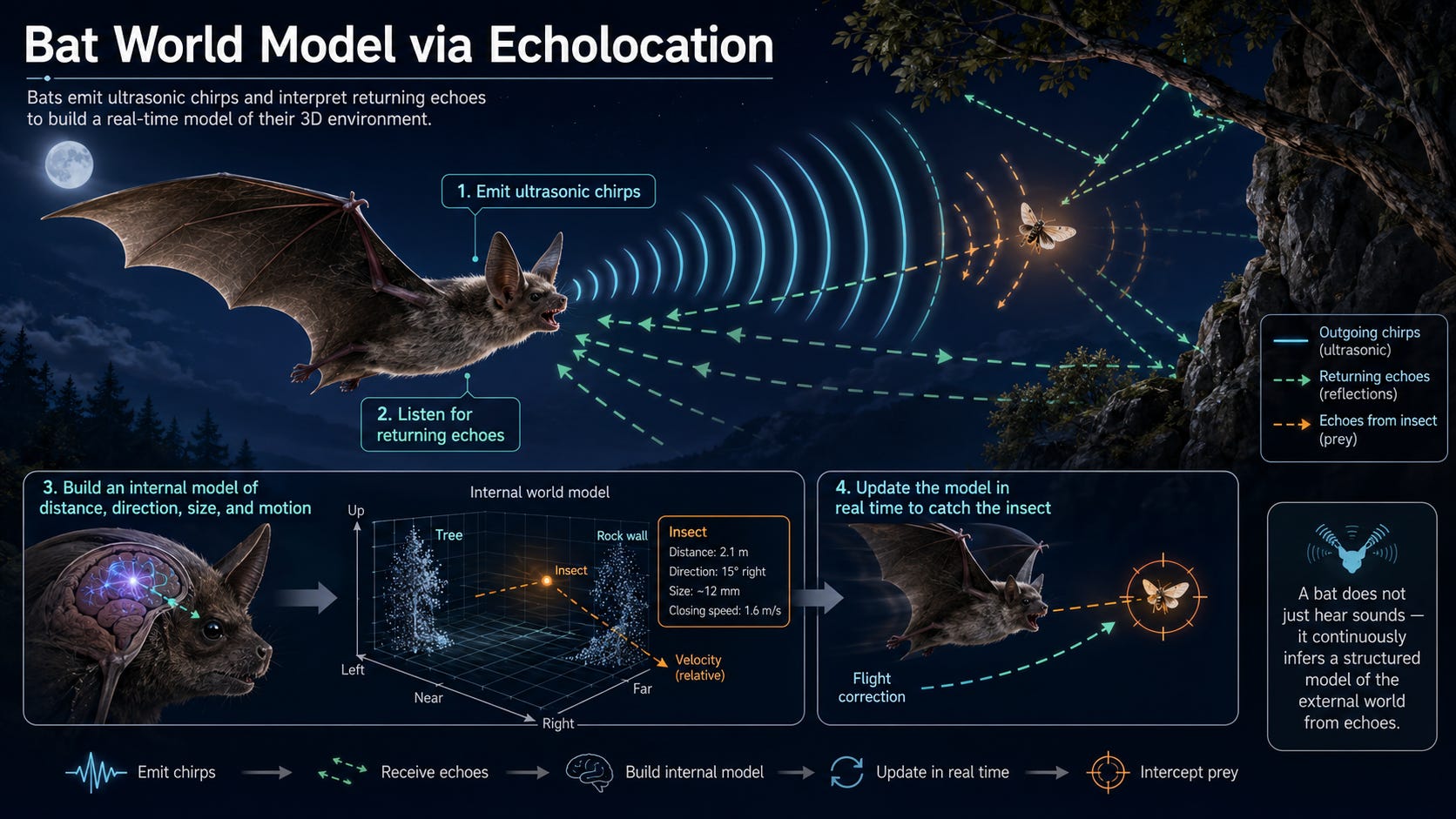
However, if you ask any physicist or engineer, they will tell you “the world is made of math.” Full stop. And AI is now getting gold on global math competitions and solving Erdős problems. So… what’s the problem?
Generally speaking, when people are criticizing LLMs they are making one (or more) of these kinds of errors:
The Category Error
Many people want an LLM to be “one size fits all problems”, otherwise it isn’t AGI. Fine, if that’s the goal. But the only reason that’s the goal is because human brains are “one size fits all.” It might not be efficient to have One Model to Rule Them All. Consider AlphaFold and AlphaProteo (Google DeepMind’s advanced biophysical models that model proteins). They have bespoke capabilities that LLMs cannot do and may never be able to do. Why? Because it’s a super powerful narrow AI. “Narrow AI” in this context means “machine learning that has one specific function.”
So when people want an LLM or AGI to excel at literally every single task imaginable, this to me registers as a category error. You do not ask a screwdriver to also be a microwave. Some tools are highly specialized, and that is actually the most efficient method. Likewise, human brains are “AGI” in the organic sense, but you never read the raw output of an MRI or CT scanner. You let the specialized machine recreate images that you can intuitively understand.
Outdated Mental Models
In other cases, people make assertions like “the world is not made of words” as if that is the end of the discussion. But “LLMs” are not just trained on words. They are trained on words, images, audio, and video (just to name a few modalities). Ever since ChatGPT 4o (the much beloved model), where the ‘o’ stood for “omni”, LLMs have been multimodal. Meaning that they do, actually, have an intuitive sense of 3D space. But as described above, 3D space is not the pinnacle of intelligence. Yes, being able to solve Moravec’s Paradox is essential to maximize automation potential, particularly in robots.
But…
People who whine and complain about world models are generally elevating sensorimotor loops to some lofty position, when it is actually a pretty small feature in the full scope of what intelligence actually is, what it can do for us, and where we will get value from. Again, I’m not saying that sensorimotor loops are not useful, they are absolutely necessary. But mice and cats have them figured out, and we don’t consider them a threat to our existence, or particularly economically useful. Thus, in these cases the person just seems to have an outdated mental model of what LLMs actually are today.
Misunderstanding of Intelligence
I’ve been alluding to this one, but by and large, people who elevate “world models” (as described) generally don’t really understand that much about intelligence. They don’t realize that abstraction and metaphor are far more important for the things that “AGI” and “ASI” are supposed to do for us than sensorimotor loops. a Sidewinder missile has very tight sensorimotor loops, and is very useful for one thing. The thing is, visuospatial intelligence is largely preverbal. Being able to dance and do cartwheels and catch bugs in midair is impressive and useful. But it’s not going to solve warp drive or quantum computing.
When you ask “what are the most useful things that AI could do for us?” the answer is stuff like “cure cancer” and “solve climate change.” World models add absolutely nothing to those tasks. Curing cancer is mostly about biophysical calculation and protein modeling (to be highly reductive). None of which involves sensorimotor loops or predicting movement in 3D space. Likewise, the premier use of AI right now is writing code, which also involves zero world modeling.
Yes, I know that the tasks we want robots to do, like underwater welding and building habits on the moon, will require more “world models” but that’s also sort of privileging something that amounts to what we call “smart hands” in the industry. “Smart hands” are just people who are dexterous enough and can follow physical process instructions without actually understanding what they are doing and why. And this is what many astronauts do already. The science experiments they carry out in orbit are often outside of their domain of expertise. They are merely following instructions and interacting with objects, energy, and tools. Robots are not so different.
Again, I’m not saying that giving a robot the ability to both understand (in the abstract) and improvise physically is not useful. It is, but it’s also on track to be a solved problem with VLA models.
Lack Historical Technical Knowledge
This is the one that is, perhaps, the most forgivable. I know about this only because I was a first mover on AI cognitive architectures, and so I went back in history to learn about cognitive architectures. The more generous definition of a “world model” goes beyond “sensorimotor loops” and into what would, by any engineer, as a cognitive architecture. These architectures were developed for autonomous machines like rovers and rockets.
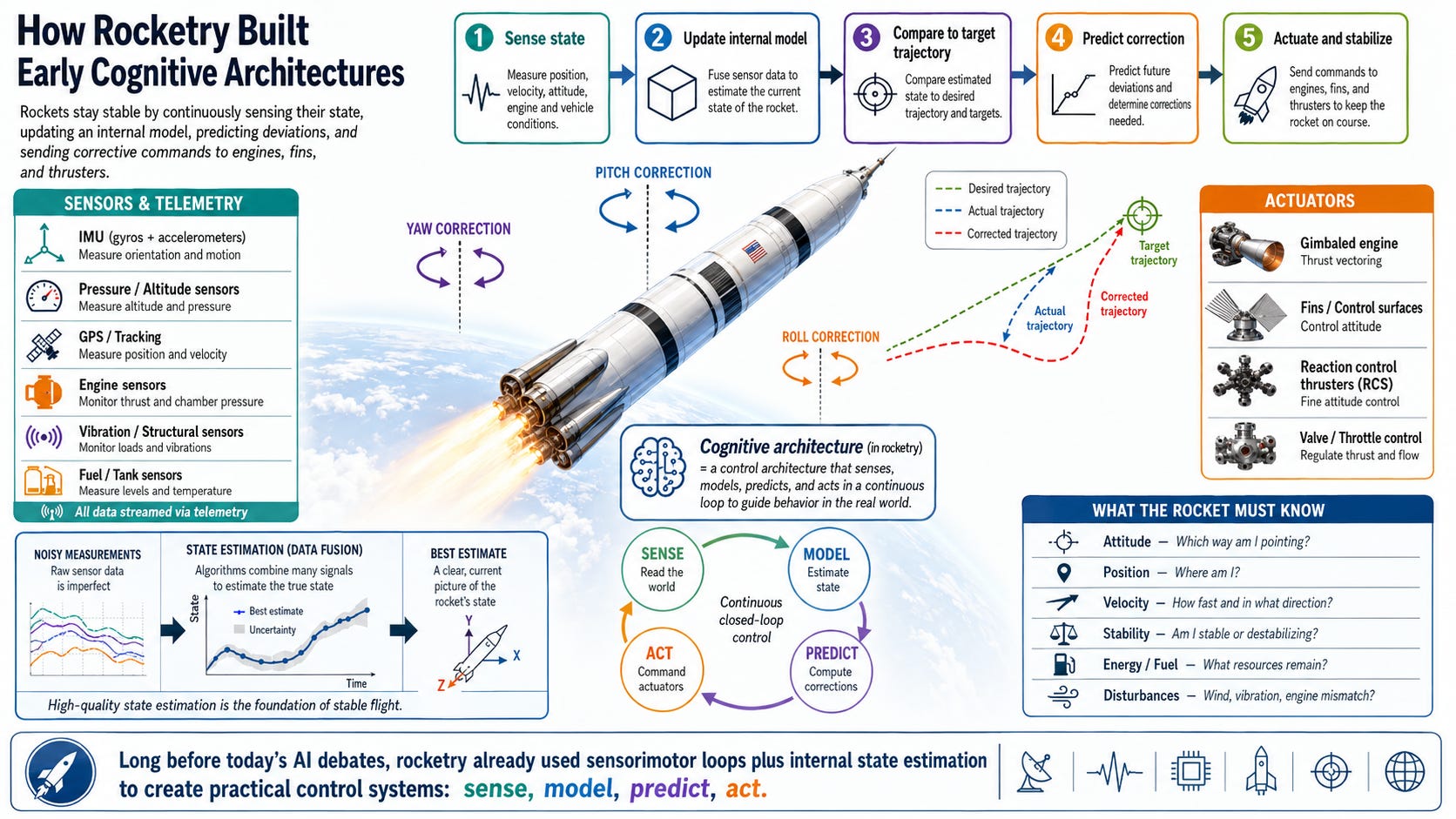
Again, very highly useful, but do you want a general purpose intelligence to be piloting a rocket? No, you want a bespoke, purpose-built set of ASICs to pilot your rocket. The general purpose general intelligence should help define the mission parameters and decide when to launch. But it should leave the fine-tuned sensorimotor control to dedicated hardware and software.
My take on a “world model.”
When you take the superset of reality, and salient subdomains, what comes to mind? Math, physics, chemistry, engineering all percolate up for me. When I think “man, I really hope that AI can help us solve chronic illness, rare disease, and aging” world models contribute exactly nothing to that conversation.
However, I also want robotics and automation to solve all human labor, to endow robots with the ability to automate the entire economy. That does require a “world model” insofar as short term understanding of physical tasks. But between VLA models and one-shot human-observation learning, I think that humanoid robots will probably master visuospatial skills relatively quickly, and people will just stop arguing about LLMs.
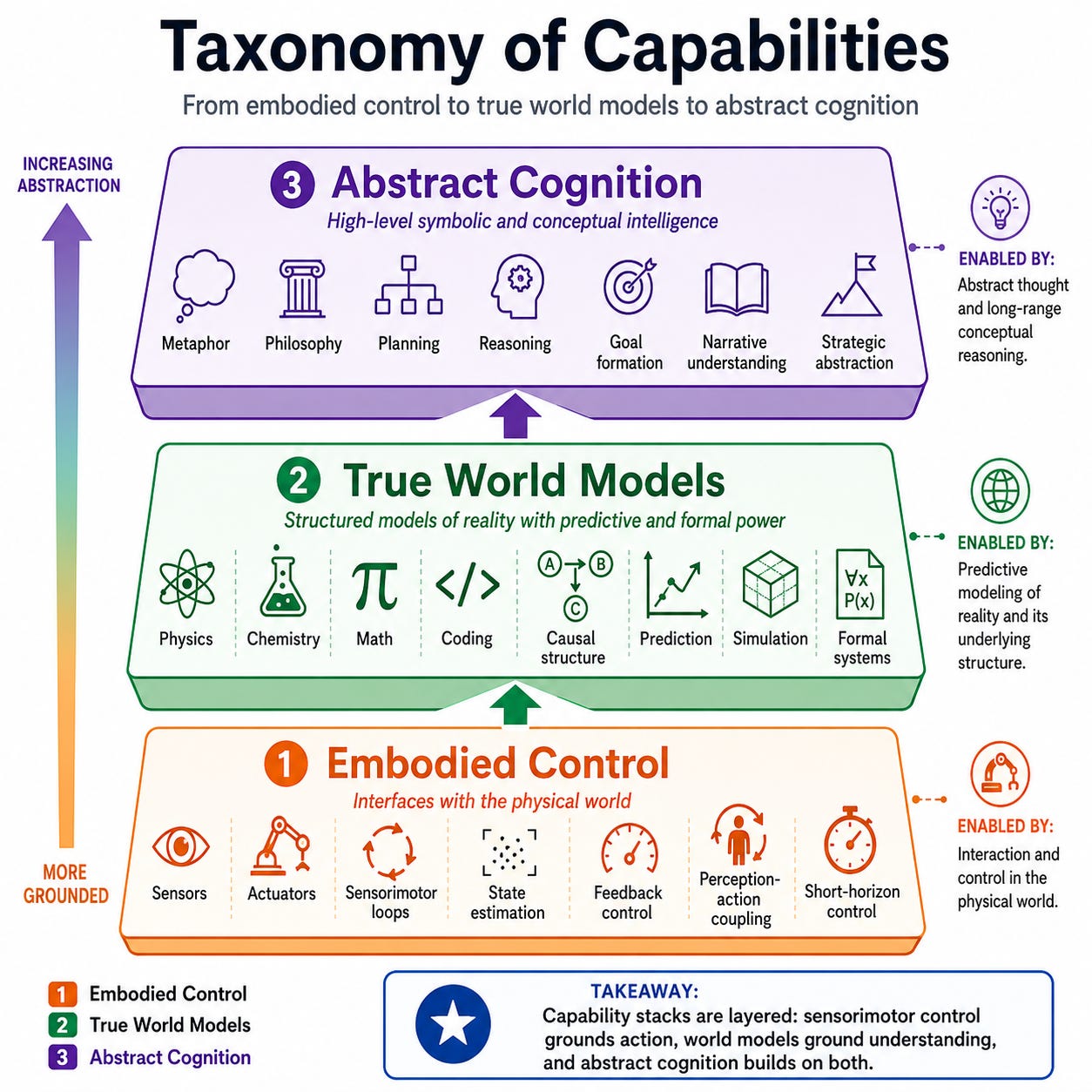
This taxonomy makes sense because it separates levels of abstraction from levels of embodiment. At the top are capabilities like metaphor, philosophy, planning, and reasoning: these are mostly about manipulating ideas, goals, narratives, counterfactuals, and symbolic abstractions. Modern LLMs are already very strong here because language is a compressed interface for human concepts. They can reason about what a person wants, compare strategies, explain tradeoffs, and generate plans. But that does not mean they automatically possess grounded control over the physical world. Abstract cognition can decide what ought to happen, but it does not by itself provide the machinery for making it happen in real time.
The middle layer is where “world models” properly live: physics, chemistry, coding, math, causal structure, simulation, and system dynamics. These are not just raw sensorimotor loops, and they are not merely verbal abstractions either. They are structured models of how things behave: forces, reactions, constraints, algorithms, trajectories, dependencies, and transformations. This is why AI progress in math, code, scientific modeling, and simulation matters so much. These domains let AI predict, explain, and generalize across situations. A system that understands equations, dynamics, causality, and executable structure is closer to modeling the world than a system that only reacts to sensory input.
The bottom layer exists because the physical world imposes real-time constraints. Sensors, actuators, perception, feedback loops, and motor control are not “lower” because they are unimportant; they are lower because they are more concrete, timing-sensitive, and hardware-bound. This is why specialized functions exist. The same architecture that is good at philosophical reasoning is not necessarily optimal for millisecond-level force control, tool alignment, grasp stabilization, or balance correction. Biological systems reflect this too: the neocortex, cerebellum, brain stem, eyes, hands, muscles, and reflex loops are specialized because the problem decomposes naturally. AI and robotics will likely follow the same pattern: abstract models for goals and reasoning, world models for prediction and structure, and specialized embodied controllers for fast, reliable action.
The Robots Are Coming
I don’t want to rain on anyone’s parade. “World models” are important, and I constantly use scare quotes because it represents a fundamental misunderstanding of what the world is, what control theory says, and the technical history of robotic automation.

We very well may end up with unified “end-to-end” models that integrate abstraction, speech, planning, memory, and low level actuation. I won’t hold my breath either way.
