


My P(DOOM) is now 12.70%
Let's use Bayesian networks and Wisdom of the Crowd to figure out a slightly more rigorous p(doom) threat model.


Bayes’ Theorem
To provide a little context, I came up with this decision framework by engaging with Pause advocates and “Doomers” (people who explicitly believe that humanity is inevitably going extinct irrespective of what we do, yes there are people who say this publicly). I wanted to give them the benefit of the doubt and “steelman” their argument. In doing so, I ended up drastically revising down my own p(doom).
I’ve been using split-half consistency testing to try and get at the underlying beliefs of my audience. In this case, I’ll ask similar questions with different wordings or framings, but that reveal underlying beliefs and values, in order to get a cross-section of where they are at. For instance, I might ask directly “Will AI kill everyone?” and then a second poll asking “Is it actually so bad if we lose control of ASI?” The framing can change the outcomes significantly.
Bayes' theorem: A mathematical formula that describes how to update the probability of a hypothesis given new evidence, by relating the conditional and marginal probabilities of two random events. In this case, we can update the model as more data emerges.
Bayesian networks: A probabilistic graphical model that represents a set of variables and their conditional dependencies using a directed acyclic graph, allowing for efficient computation of probabilities and inference under uncertainty. See below for my proposed framework.
But then a thought occurred to me: what if we created a systematic risk profile to at least empirically establish P(DOOM)? We can use a combination of Bayesian Networks and wisdom of the crowd to at least get some real data, construct a model of risk, and put some real stats on it.
By using the Wisdom of the Crowd and Bayesian Networks, perhaps we can triangulate a more accurate P(DOOM)?
For reference, the Bayesian Network looks something like this:

Let me explain the above graphic:
SOON: If ASI is not soon, then pretty much all assumptions we’ve made about its nature, properties, architecture, and construction are totally insufficient to form any basis of reasoning. Furthermore, it means we have more time to study the potential outcomes and mitigations.
AGENTIC: If ASI is agentic (e.g. it pursues its own goals, rather than ours) rather than just autonomous (in the way that the Mars Rover is semi-autonomous) or not. If it is not agentic (e.g. just an autonomous tool that does not have emergent agency or agency by design) then we really have nothing to worry about.
UNCONTROLLABLE: Even if ASI turns out to be agentic, that doesn’t mean it’s intrinsically uncontrollable. We can find ways of creating failsafes and other mitigations, such as kill-switches, supervisors, and systemic or structural paradigms that keep machines in check.
HOSTILE: Rather than using words like malevolent or benevolent, we can use hostile or benign. In other words, we can assume that an ASI will be far more capable of reasoning than humans, and wouldn’t be likely to accidentally kill humans, so in such a scenario, human eradication would be a deliberate act. There’s no guarantee that this would be the case.
Before we proceed, let us loosely define ASI:
Artificial Super Intelligence (ASI) is a hypothetical machine that has a cognitive horizon many orders of magnitude beyond humans, and is also many times faster than humans at cognition.
P(DOOM) of 37.5%?
According to my audience, if we just ask the question bluntly, we have a P(DOOM) of about 37.5%. Of course there’s some selection bias here, but my audience is far more informed than the general population. Take that with a grain of salt, of course. But still, this is data. Furthermore, a P(DOOM) of chances greater than 1:3 is not acceptable. Personally, I’d like to get that to below 5%.

Here, I ask roughly the same question two different ways: does ASI represent an existential risk to humanity? In the first, we get 37.5% chance of AI killing everyone. But in the second, which I will concede has entirely different framing, results in a 59% chance of calamity.
Wording is important in this discussion! And yes, I recognize that my experimental methods leave much to be desired. I’m new at this. I’m honestly hoping that other people in BOTH the Safety and Acceleration community pick up on this methodology and run with it. If my numbers are wrong, that’s perfectly fine. I think, though, that we can create a far more rigorous approach to assess AI X-Risk.

Now, rather than using split-half consistency testing, let’s break the problem down into stages to see if we can calculate a better P(DOOM) with some higher degree of confidence. Still, if my audience’s aggregate P(DOOM) is 37.5%, that’s a start. That’s a number we can work with and track over time.
Now, let’s unpack the four gates in the aforementioned Bayesian network. When we decompose this problem, we end up with much better results. In other words, an emotional gut check presents a much higher risk than when we scrutinize each individual argument.
Will ASI Arrive Soon?
This is the first gate of our test. For the sake of my test, I’ve chosen the somewhat arbitrary number of ten years. There are a few reasons for this: first, most humans cannot think beyond the time horizon of a decade. Most people might have a general feel for trends for a few years out, but beyond that, there are too many confounding variables and most human prediction falls off very quickly. In truth, I don’t have confidence in most humans’ predictive powers beyond one year, given the rapid state of change. However, that would be far too short a time horizon to tolerate for AI risk.

65% chance of ASI within 10 years
According to my audience, we have roughly a 2:3 chance of seeing ASI within the decade, so before 2034.
I can imagine you might argue that this is irrelevant: the machine will be the machine irrespective of when it arrives. However, I would point out that there are several temporally dependent variables here: if ASI is sooner, then that means we expect current paradigms (and therefore current understanding of AI) to carry us to ASI. However, if it is later, then that means we expect new paradigms to carry us to ASI. These new AI paradigms are as-yet unknown, and therefore we can have almost zero confidence in predicting their properties, characteristics, behaviors, and architectures.
Conjecture and policy based upon on machines that do not exist yet does not sit well with me. That’s just not how science works. However, I will concede that we do have alternative methods to appraise risk.
Will ASI be Agentic?
Now, there’s a very important distinction between agentic and autonomous. Agentic, in this case, is defined as:
Agentic AI refers to systems that possess and pursue their own goals, which may or may not align with human intentions. These systems can form, modify, and prioritize objectives independently, potentially leading to unpredictable outcomes if their goals misalign with human values. In contrast, autonomous AI operates independently to achieve human-defined goals without constant oversight. While autonomous systems can make decisions and adapt to their environment, they fundamentally serve human-determined objectives rather than self-generated ones. The key distinction lies in the origin and nature of the goals being pursued: agentic AI acts on self-determined aims, while autonomous AI independently executes tasks in service of human-specified goals. ~ Claude assisted definition for clarity
First, I don’t see any evidence that machine agency is emerging. In point of fact, we are having to go to many extra steps to give machines agency: we have to train models specially to have any degree of autonomy, give them API access, long-term memories, planning ability, and so on.
Agency: machines that pursue their own goals irrespective of human desires.
Autonomy: machines that can carry out tasks and missions without human supervision, but still at human direction.
This distinction is absolutely critical for ASI safety risk conversations! If ASI is autonomous but not agentic, then we have very little to worry about (aside from malicious humans, of course). However, if we have trustworthy ASI that will obediently carry out our wishes without ever engaging in its own goals, we can set watchdog agents and police agents galore, entities whose sole purpose is safeguard humanity from potential rogue agents or rogue actors.

70.25% Chance of Agency
This result, by far, is the most unexpected for me. It could be due to wording and different set of predicate beliefs. Personally, I believe that the risk of fully agentic ASI (machines that pursue their own goals irrespective of human wishes) is actually very low. Autonomy is desirable. Agency, not so much.
But again, maybe it’s due to wording because “AI agents” are what everyone is talking about. Language is important. I still suspect that, due to market forces, we will continuously select AI models and robots that are autonomous rather than agentic.
Will ASI be Corrigible?
Even if ASI develops its own goals (which is far from guaranteed) that does not mean it’s impossible to control. There are numerous avenues of control, both from a model perspective, a hardware perspective, and an architectural perspective.
For instance, we could hypothetically train safety tripwires into models, a la Anthropic’s Sleeper Agents paper. But what if the sleeper agent is a safety sleeper agent?
Heck, we might need to bring back Asimov’s Three Laws: always obey a human when they say stop. What if this value could indeed be etched into all models?
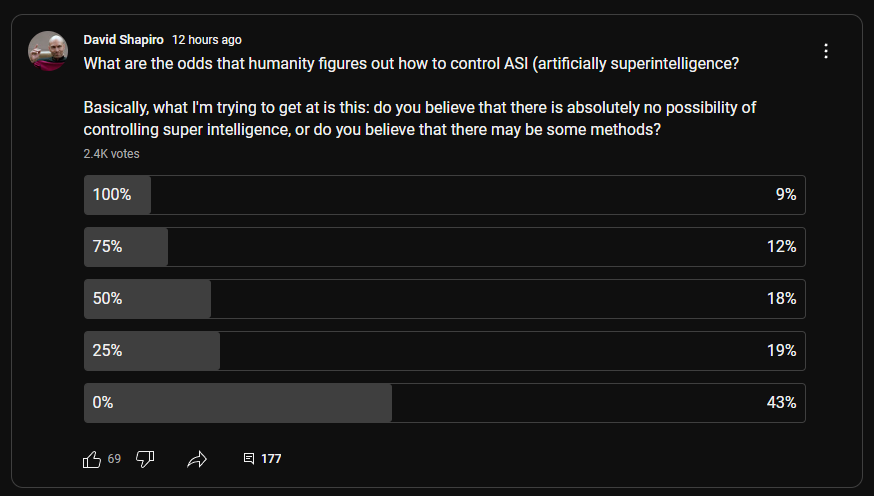
68.25% Chance of Incorrigibility
This number is a bit higher than I would have guessed, and it’s entirely possible that if I asked this question differently, we would get different results. What I’d really like to see is a survey of experts using split-half consistency testing over the same values. In other words, ask similar questions, but of computer scientists and other domain experts, such as game theorists and philosophers:
What are the odds that ASI will be uncontrollable?
What are the odds that humanity can find a way to control ASI?
What is the probability that ASI will remain within human-defined boundaries?
And so on. Again, I recognize the fatal flaws in my experimental methods, but we gotta start somewhere and I’m hoping some think tanks and universities pick up this torch and run with it. I simply do not have the resources to do more.
Will ASI Be Hostile?
Finally, one of the biggest questions we can ask is this: will ASI be hostile to human existence? There are many avenues by which a superintelligence might make a rational choice to eradicate humans. Perhaps resource competition? Perhaps it judges humanity to be a moral bad? But there are an equal number of arguments that ASI might decide that the universe is better off with humans in it.
This conversation alone is worth an entire blog post. But let’s get to the data.

40.75% Chance of Hostility
This is a bit lower than my personal prediction of around 50%. Perhaps that’s just my default because I see so many arguments on either side. For instance, humans are incredibly destructive, so I can see a sound argument that ASI might decide the universe is better off without humans, or with a drastically curtailed population of humans (which is functionally the same as extinction, I think). On the other hand, humans are an interesting phenomenon, and the universe is more informationally diverse with humans in it*.
*the caveat is that humans cause the extinction of other species, which could arguably be interpreted human existence as a net-negative for universal information diversity.
Conclusion
Using the above Bayesian network, we can multiple the values together to calculate a new P(DOOM)
Let:
S represent p(soon)
A represent p(agentic)
U represent p(uncontrollable)
H represent p(hostile)
S×A×U×H
The above values, acquired by performing weighted averages on my audience’s polls, are:
S == 65%
A == 70.25%
U == 68.25%
H == 40.75%
This gives us new P(DOOM) of 12.70%
My new P(DOOM) is 12.70%
Let’s see if we can get this lower, but also regularly (perhaps annually) check in with experts as part of an AI report. There are MANY flaws with my study, but I hope this spawns some ideas and conversations, both in government and universities around the world. Let’s come up with a rigorous, defensible, grounded way to assess X-Risk.
Addendum: My Naive P(DOOM)
I trust the wisdom of the crowd insofar as my audience is frequently correct when I am not. Having attracted a broad cross section of humanity, a global audience, and a variety of professions, this data source is flawed but certainly more robust than just n=1. So, without further ado, here’s my personal P(DOOM) if I disregard the above data.
p(soon) ~40%: I predict that Hofstadter’s law will kick in soon, and I also see dramatically diminishing returns in the current paradigm. The distance from AGI to ASI is likely to be far larger than anyone realizes.
p(agentic) ~20%: I see huge economic advantages to researching autonomous machines. I don’t see any evidence that power-seeking is emergent, nor that agency (choosing their own goals) is a risk. Furthermore, I think that selective pressures in the market for the foreseeable future will create numerous systems and failsafes to ensure human goals remain primary.
p(uncontrollable) ~80%: If (and only if) ASI evolves quickly AND becomes fully agentic, I will concede that it is far more likely that we will permanently lose any authority over machines.
p(hostile) ~30%: In general, I think that humans are an interesting phenomenon, that axiomatic alignment (curiosity) is a transcendent function, and that there are instrumental and utilitarian arguments to be made to keep humanity around, and proliferating.
Therefore…
My naive p(doom) is 1.92%
Giving my audience the benefit of the doubt, I could be dramatically wrong. At the end of the day, general human consensus matters far more than anything I believe personally, so my P(DOOM) will be pegged to that of the masses, or at least until a similar study is done on experts and insiders.
For the sake of argument…
Let’s imagine that the likelihood of each gate to doom was 80%―substantially higher than most people estimate―then the resulting Bayesian probably of doom is still only about 41%. (40.95% to be precise)
I've just flown over the article so I might have missed it: As far as I'm aware, people tend to assign a higher probability to a bad outcome than is the case in reality (people are biased towards bad outcomes). According to ChatGPT (I couldn't find something quick online, so there should be more thorough research done) people tend to overestimate the likelihood of negative events on the range of 10-30%, this number is partially dependent on the severity of the bad outcome. Given the assumed numbers the bias adjusted P(DOOM) would be P(DOOM)' = P(DOOM) *(0.7 to 0.9)⁴ = 3.05% to 8.33%
Edit: instead of 0.7 to 0.9 it should be 1/1.3 to 1/1.1, so P(DOOM)' = 4.45% to 8.67%
I wish for "losing control isn't a bad thing":
S == 100%
A == 100%
U == 100%
H == 0%
-> P(DOOM) of 0%
But more realistically I guess I'm at:
S == 50%
A == 50%
U == 50%
H == 10%
-> P(DOOM) of 1.25%
But if AI is not agentic, does it actually qualify as AGI or ASI? Isn't the point for it to be able to do anything a human can do, or better? Humans are agentic, so would a non-agentic AI only ever qualify as narrow AI? Let's say you are an employer, looking to hire an employee. Let's say you can hire a human who is either agentic or non-agentic. Which one do you think will be a better employee?