


Math: We're no where near the top of AI capabilities
Humans generalize far better than AI on far less data. This has huge implications for how far AI can go. Let's run some numbers!

Welcome to 2025! My second-most viral tweet of 2024 was as follows:
This tweet came as a response to a repost of an Ilya Sutskever slide presentation:

TLDR: We’ve pretty much consumed most of the data available to us, with the exception of some of the most valuable paywalled data. OpenAI scraped “public domain videos” for training Sora and others. Google has direct access to all of YouTube while Meta has direct access to Facebook and Instagram.
Some of the valuable paywalled data that I refer to is scientific publications. Not everything is on the internet. Not every book is digitally available either. Furthermore, not all data is created equal. Anyways, my point here is that AI is presently naively trained using brute force methods and as such it requires huge amounts of data (several orders of magnitude more data than humans) to learn language and facts.
By age 4, children generally should have heard about 40 million words, or about 70 million “tokens” in AI training data terms. Now, I will concede that this is comparing apples to oranges because children hear words with tonality and in context. Our multimodal learning instinct for language means we do not acquire language in a total vacuum. Furthermore, between the ages of 2 and 5, children generally ask about 40,000 questions, meaning that they are actively integrating and testing their world models, and this does not even begin to examine the role that play, experimentation, and embodied learning provides, at least for creating basic world models.
However, consider that an entire child’s life, up through adolescence, could be represented by just 87,500 hours of video, meaning it includes audio, video, context, language, and more nonverbal information. This, by comparison, YouTube gets 720,000 new hours of video content every single day. Llama 3 was trained on 15 trillion tokens.
My estimation here is that, by age 8, a child has learned language and a powerful visuospatial world model, and does so with somewhere between a million and billion times less data than Llama 3. Now, arguably Llama 3 is better at math, science, and world facts. So again, comparing apples to oranges.
But what about energy?
By age 8, a child’s body has consumed about 3.5 million kcal, or 4 MWh of energy. By contrast, Llama 3 required about 39 million GPU-hours, which amounts to roughly 500MWh of juice. Now, this is where it gets interesting, because that’s about 100x more energy than training a child up to age 8, but of course Llama can be copy/pasted infinitely, whereas children cannot.
Some Implications
A human child seems to be far more data and energy efficient than even the best models today. The only thing that AI has on us humans (in terms of efficiency) is that the final product can be replicated infinitely (children cannot be copy/pasted) and that AI can be trained massively parallel (cramming millions of GPU hours into a few weeks).
My point here is not to say “Aha! See! AI is stupid and will never overtake us!” My primary point is that human brains prove that there are far more algorithmic efficiencies that we can discover, as well as hardware efficiencies that evolution already solved.
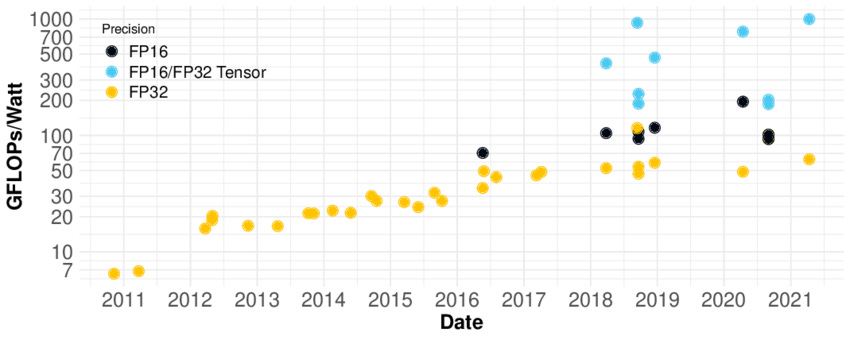
Our brains are about a million times less energy-demanding than current supercomputers. However, we’ve been saying that for at least 20 years. Every next generation of supercomputer is heralded as having human-brain-level-FLOPs, but every time, we realize that the human brain is several orders of magnitude more efficient than we thought. Now, we’re on the cusp of believing that the human brain exploits quantum physics to do its processing.
In plain English…
Okay, enough beating around the bush…
In plain English, what I’m saying is that Mother Nature has already solved computation and learning to a degree at least a million times more data-efficient than the AI we’ve got now, and at least 100x more efficient just for training (and possibly a million times more efficient at inference).
However, this is all still comparing apples to oranges. There are physical affordances that make training AI not just structurally different (AI models can be copied ad infinitum) but furthermore, the way that AI forms abstractions also seems to be somewhat different from humans. With that being said, we’re finding more and more artificial/neurological convergences between human brains and AI.
When we take a look at the basic physics of what’s going on, in absolute terms of data and energy, we can easily conclude that AI has many, many, many cycles left to go before we reach any sort of plateau. Whether or not current paradigms will keep scaling is irrelevant when you take the long view. Vacuum tubs and relays gave way to transistors, which gave way to lithographic integrated circuits. AI today is equivalent to relay-based computation.
*(children cannot be copy/pasted)* peak daveshap experience
thanks for insights as always!
Humans naturally integrate multiple types of sensory information and experiences:
Multi-modal learning: As you noted, a child experiences dogs through sight, sound, touch, smell, and even interactions - they get a rich, multi-sensory understanding of what "dog" means
Context: Children see dogs in different situations - at home, in parks, on walks - learning about their behaviours and roles in human life
Temporal understanding: They observe how dogs move, play, and interact over time, not just static snapshots
Social learning: They also learn about dogs through language, stories, and how other people interact with dogs
Current AI systems are often trained on just one type of data (like images) in isolation. While there is progress in multi-modal AI that can process both images and text, or video and audio together, these systems still don't integrate information in the rich, embodied way that humans do naturally from birth.
This "embodied cognition" - learning through multiple senses and physical interaction with the world - might be one of those key algorithmic differences the tweet is talking about. It could help explain how humans can build such robust understanding from relatively few examples, compared to AI systems trained on millions of isolated data points.